Benchee
我們無法靠猜測來得知哪些函數快而哪些慢 - 當想知道時需要實際量測。 這就是基準測試(benchmarking)出場之時。 在本課程中,將學習測量程式碼的速度是有多麼容易。
關於 Benchee
雖然有一個 Erlang 函數 可用於函數執行時間的基本度量,但使用起來卻不如其他可用的工具,它並不能進行多次測量以獲取有用的統計資訊,因此我們使用 Benchee。 Benchee 提供了各種統計資料,可以方便地比較各種情境,該功能非常強大,可以用不同的輸入測試基準測試中的函數,還可以使用幾種不同的格式器來顯示結果以及根據需要編寫格式器。
使用方法
要將 Benchee 加入到專案中,請將其作為相依性加入到的 mix.exs 檔案中:
defp deps do
[{:benchee, "~> 1.0", only: :dev}]
end然後執行:
$ mix deps.get
...
$ mix compile第一個指令會下載並安裝 Benchee。 可能會要求同時安裝 Hex。 第二個則會編譯 Benchee 應用程式。 現在,準備編寫第一個基準測試。
在開始之前的重要注意事項: 進行基準測試時,不要使用 iex 是很重要的,因為它的行為不同,並且通常有可能比你在正式環境中使用的程式碼速度還慢。
因此,現在建立一個名為 benchmark.exs 的檔案,然後在該檔案中加入以下程式碼:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})現在執行基準測試,呼用:
mix run benchmark.exs現在應該在控制台中看到類似以下的輸出內容:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median 99th %
flat_map 2.40 K 416.00 μs ±12.88% 405.67 μs 718.61 μs
map.flatten 1.24 K 806.20 μs ±20.65% 752.52 μs 1186.28 μs
Comparison:
flat_map 2.40 K
map.flatten 1.24 K - 1.94x slower +390.20 μs當然,根據執行基準測試的機器規格,系統資訊和結果可能會有所不同,但是這些常規資訊都應該存在。
乍看之下,Comparison 部分展示了 map.flatten 版本比 flat_map 慢 1.94 倍。它還表明,平均要慢 390 微秒左右。這都有助於更進一步了解!但是,現在來看看獲得的其他統計資料:
- ips - 這代表「每秒疉代次數」,它告訴我們可以在一秒鐘內執行給定函數的頻率。 對於此指標,數字越大越好。
- average - 這是給定函數的平均執行時間。 對於此指標,數字越小越好。
- deviation - 這是標準偏差,它告訴我們每次疉代的結果在最終結果中有多少變化。 在此以平均值的百分比形式給出。
-
median - 當對所有測量時間進行排序時,這是中間值(或當樣本數為偶數時,兩個中間值的平均值)。
由於環境不一致,它會比
average更穩定,並且更有可能反映出正式環境中程式碼的正常性能。 對於此指標,數字越小越好。 - 99th % - 所有測量的 99% 都比這快,這使得這種情況為 最差 效能。越低是越好。
還有其他可用的統計資料,但是這五個經常是最有用的,並且通常用於基準測試,這就是為什麼它們以預設排版程式顯示的原因。 要了解有關其他可用指標的更多資訊,請查看 hexdocs 上的文件。
配置
Benchee 最棒的部分之一是這些可用的配置選項。 接著將先介紹基礎知識,因為不需要程式碼範例,然後將說明如何使用 Benchee 的最佳功能之一 ー 輸入。
基礎
Benchee 具有大量的配置選項。
在最常見的 Benchee.run/2 界面中,會以可選關鍵字列表的形式作為第二個參數傳遞:
Benchee.run(%{"example function" => fn -> "hi!" end},
warmup: 4,
time: 10,
inputs: nil,
parallel: 1,
formatters: [Benchee.Formatters.Console],
print: [
benchmarking: true,
configuration: true,
fast_warning: true
],
console: [
comparison: true,
unit_scaling: :best
]
)可用選項如下(也記錄在 hexdocs)中。
- warmup - 在開始實際測量之前,執行基準測試情景前不測量時間的時間。 此參數模擬「暖式」的執行期系統。 預設為 2。
- time - 每個基準測試方案應執行和測量多長時間的時間(以秒為單位)。 預設為 5。
- memory_time - 每個基準測試情景應測量多長時間的記憶體消耗時間(以秒為單位),將稍後再討論。預設為0。
-
inputs - 其中表示輸入名稱的字串為鍵,而實際輸入為值的映射。也可以是以
{input_name, actual_value}形式的 tuple 列表。 預設為nil(無輸入)。 將在下一節中詳細介紹。 -
parallel - 用於基準測試函數的處理程序數目。
因此,如果設定
parallel: 4,則將產生 4 個處理程序,這些處理程序在給定的time內都執行相同的函數。 當這些都完成後,將為下一個函數生成 4 個新處理程序。 這樣可以同時提供更多資料量,但也會給系統帶來負擔,干擾基準測試結果。 這在模擬負載情況下的系統時可能很有用,尤其在負載上,但應謹慎使用,因為這可能以不可預測的方式影響結果。 預設為 1(表示沒有以並行執行)。 -
formatters - 格式化器列表(作為實現格式器行為的模組),該模組的 tuple 及其應採用的選項或格式器函數。它們在使用
Benchee.run/2時執行。 函數需要接受一個參數(具有所有資料的基準測試套件),然後使用該參數產生輸出。 預設為內建控制台格式器Benchee.Formatters.Console。 在後面的部分中會詳細介紹。 - measure_function_call_overhead - 測量一個空函數呼用花費的時間,並從每個測得的執行期中扣除。有助於提高那些非常快速的基準測試準確性。預設為 true。
-
pre_check - 在基準測試進行測量之前,是否每個輸入都執行每項工作 - 包括情景之前或之後給出的所有輸入或每個掛鉤 - 以確保程式碼無錯誤執行。這樣可以節省開發套件時的時間。預設為
false。 -
save - 指定一個
path來儲存當前基準測試套件的結果,並用指定的tag進行標記。請看 Benchee 文件中的 Saving & Loading。 - load - 載入一個或多個已保存的套件來與當前的基準測試進行比較。可以是字串,也可以是字串或模式的列表。 請看 Benchee 文件中的 Saving & Loading。
-
print - 具有以下選項的映射或關鍵字列表,它們是以 atom 為鍵和
true或false為值 。 這使我們可以控制在標準基準測試過程中是否列印由 atom 的輸出識別。 預設情況下,所有選項都是啟用的 (true)。 選項有:- benchmarking - 在 Benchee 開始對新工作進行基準測試時輸出。
- configuration - 在基準測試開始之前,將輸出已配置的基準測試選項的摘要,包括預估的總執行時間。
- fast_warning - 如果函數執行得太快,則會顯示警告,從而可能導致不正確的測量。
-
unit_scaling - 選擇持續時間和計數單位的策略。
在縮放值時,Benchee 尋找「最符合(best fit)」單位(結果至少為 1 的最大單位)。
例如,
1_200_000擴展為 1.2 M,而800_000擴展為800K。 當列表中的各個值可能具有不同的最佳擬合單位時,單位縮放策略將決定 Benchee 如何為整個值列表選擇最佳擬合單位。 有四種策略,均以 atom 形式給定,預設為:best:- best - 最頻繁使用的最佳擬合單位。 平局(tie results)導致選擇了較大的單位。
- largest - 使用最大的最佳擬合單位
- smallest - 使用最小的最佳擬合單位
- none - 沒有單位縮放發生。 持續時間以納秒(nanoseconds)為單位顯示,而 ips 計數為無單位顯示。
-
:before_scenario/after_scenario/before_each/after_each- 在這裡不會涉及太多內容,但是如果需要在基準測試函數之前 / 之後做一些事情而又無法對其進行衡量,請參考 Benchee 的 hooks 章節
輸入
使用能反應該函數在現實世界中可能實際運行的資料來進行該函數的基準測試非常重要。
通常,函數在小型資料集和大型資料集上的行為可能有所不同!這就是 Benchee 的 inputs 配置選項出現的地方。
這使你可以測試相同的函數,但使用任意數量的不同輸入,然後可以查看每個基準測試的結果。
因此,現在再次看一下原始範例:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})在該範例中,僅使用一個從 1 到 10,000 的整數列表。 現在更新它以使用幾個不同的輸入,以便可以看到越來越大的列表會發生什麼事。 因此,打開該檔案,將其更改為如下所示:
map_fun = fn i -> [i, i * i] end
inputs = %{
"small list" => Enum.to_list(1..100),
"medium list" => Enum.to_list(1..10_000),
"large list" => Enum.to_list(1..1_000_000)
}
Benchee.run(
%{
"flat_map" => fn list -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn list -> list |> Enum.map(map_fun) |> List.flatten() end
},
inputs: inputs
)
你會注意到兩個區別。
首先,現在有一個 inputs 映射,其中包含輸入到函數的資訊。
我們會將輸入映射作為配置選項傳遞給 Benchee.run/2。
並且由於函數現在需要接受參數,因此需要更新基準測試函數以接受參數,所以不要:
fn -> Enum.flat_map(list, map_fun) end而改為這樣:
fn list -> Enum.flat_map(list, map_fun) end再次使用以下指令執行它:
mix run benchmark.exs現在,應該在控制台中看到如下輸出:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: large list, medium list, small list
Estimated total run time: 42 s
Benchmarking flat_map with input large list...
Benchmarking flat_map with input medium list...
Benchmarking flat_map with input small list...
Benchmarking map.flatten with input large list...
Benchmarking map.flatten with input medium list...
Benchmarking map.flatten with input small list...
##### With input large list #####
Name ips average deviation median 99th %
flat_map 13.20 75.78 ms ±25.15% 71.89 ms 113.61 ms
map.flatten 10.48 95.44 ms ±19.26% 96.79 ms 134.43 ms
Comparison:
flat_map 13.20
map.flatten 10.48 - 1.26x slower +19.67 ms
##### With input medium list #####
Name ips average deviation median 99th %
flat_map 2.66 K 376.04 μs ±23.72% 347.29 μs 678.17 μs
map.flatten 1.75 K 573.01 μs ±27.12% 512.48 μs 1076.27 μs
Comparison:
flat_map 2.66 K
map.flatten 1.75 K - 1.52x slower +196.98 μs
##### With input small list #####
Name ips average deviation median 99th %
flat_map 266.52 K 3.75 μs ±254.26% 3.47 μs 7.29 μs
map.flatten 178.18 K 5.61 μs ±196.80% 5.00 μs 10.87 μs
Comparison:
flat_map 266.52 K
map.flatten 178.18 K - 1.50x slower +1.86 μs現在,可以按輸入查看基準測試資訊。 這個簡單的範例並沒有提供任何令人驚訝的見解,但是你會驚訝於日輸入量級而帶來多少的性能改變!
格式器(Formatters)
在控制台看到的輸出是衡量函數執行時間的有用起點,但這不是你的唯一的選擇! 在本節中,將簡要介紹其他三個可用的格式器,並根據需要淺嘗撰寫格式器所需執行的操作。
其他格式器(Formatters)
已經看到 Benchee 內建了一個控制台格式器,但是還有其他三個官方支援的格式器 -
benchee_csv、
benchee_json 和
benchee_html。
它們中的每一個都會符合你期望它們做的,即將結果寫入指定的文件格式,以便可以進一步使用任何所需的格式來處理結果。
每個格式器都是一個單獨的套件,因此要使用它們,需要將它們作為相依性加入到 mix.exs 檔案中,如下所示:
defp deps do
[
{:benchee_csv, "~> 1.0", only: :dev},
{:benchee_json, "~> 1.0", only: :dev},
{:benchee_html, "~> 1.0", only: :dev}
]
end
儘管 benchee_json 和 benchee_csv 很普通,但是 benchee_html 實際上 具有 全部功能!
它可以幫助你輕鬆地從結果中生成精美的圖形和圖表,甚至可以將它們導出為 PNG 圖像。
如果對它有興趣,請查看此 html 報告範例,其中包括類似以下的圖形:
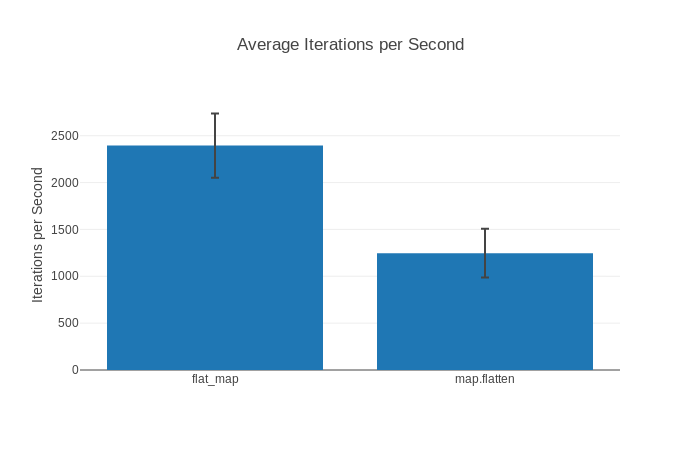
所有這三種格式器都在各自的 GitHub 上有詳細的文件說明,因此在這裡不介紹它們的細節。
自訂格式器
如果所提供的四種格式器不夠用,還可以編寫自訂的格式器。
編寫格式器非常簡單。
需要編寫一個接受 %Benchee.Suite{} 結構體的函數,然後可以從中提取所需的任何資訊。
有關此結構體中確切內容的資訊,可在 GitHub 或 HexDocs 找到。
如果想查看哪些類型的資訊可用於編寫自訂格式器,則程式碼庫是文件齊全且易於閱讀。
你還可以編寫功能更全面的格式器,該格式器採用 Benchee.Formatter behaviour 而在這裡將緊貼更簡單功能的版本。
現在,將在下面展示一個自訂格式器的簡要範例,以說明其簡易。 假設只需要一個最小限度的格式器,它可以列印出每種情況的平均執行時間 - 可能會像是這樣的:
defmodule Custom.Formatter do
def output(suite) do
suite
|> format
|> IO.write()
suite
end
defp format(suite) do
Enum.map_join(suite.scenarios, "\n", fn scenario ->
"Average for #{scenario.job_name}: #{scenario.run_time_data.statistics.average}"
end)
end
end然後可以像這樣執行基準測試:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
formatters: [&Custom.Formatter.output/1]
)當現在執行自訂格式器時,將看到:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Average for flat_map: 419433.3593474056
Average for map.flatten: 788524.9366408596記憶體
我們幾乎一路走到底,但是卻一直沒有告訴你 Benchee 最酷的功能之一:記憶體測量!
Benchee 能夠測量記憶體消耗,但僅限於執行基準測試的過程。它無法追蹤當前其他處理程序(例如 worker 池)中的記憶體消耗。
記憶體消耗包括在基準測試方案中使用的所有記憶體,也包括垃圾回收的記憶體,因此它不一定代表最大處理程序所需的記憶體大小。
如何使用它?只需使用 :memory_time 選項!
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 0 ns
time: 0 ns
memory time: 1 s
parallel: 1
inputs: none specified
Estimated total run time: 2 s
Benchmarking flat_map...
Benchmarking map.flatten...
Memory usage statistics:
Name Memory usage
flat_map 624.97 KB
map.flatten 781.25 KB - 1.25x memory usage +156.28 KB
**All measurements for memory usage were the same**如你所見,當所有採樣都是相同時,Benchee 不會費心地顯示所有統計資訊。這實際上很常見,如果你的函數不包含一定的隨機性。如果總是一直告訴你相同的數字,那麼所有的統計數據會有什麼用處?
Caught a mistake or want to contribute to the lesson? Edit this lesson on GitHub!