Benchee
どの機能が速くて、どの機能が遅いのか、推測することはできません。気になるときには実測が必要です。 そこで、ベンチマークの出番です。 このレッスンでは、コードの速度を測ることがいかに簡単かを学びます。
Bencheeについて
Erlangの関数は関数の実行時間の基本的な測定に使えますが、利用できるツールの中では使い勝手が悪く、有用な統計を取るために複数の測定値を得ることができません。そこで、Benchee を使うことにします。 Bencheeは、シナリオ間の比較を容易にするさまざまな統計、ベンチマークしている関数への異なる入力をテストできる素晴らしい機能、結果の表示に使用できるいくつかの異なるフォーマッター、さらに必要に応じて独自のフォーマッターを作成する機能を提供してくれます。
使用方法
Bencheeをプロジェクトに追加するには、mix.exs ファイルに依存関係として追加してください。
defp deps do
[{:benchee, "~> 1.0", only: :dev}]
endそして、次のように呼び出します。
$ mix deps.get
...
$ mix compile最初のコマンドは、Bencheeをダウンロードし、インストールします。Hexも一緒にインストールするように言われるかもしれません。2つ目はBencheeのアプリケーションをコンパイルします。これで最初のベンチマークを書く準備ができました。
始めるにあたって重要な注意: ベンチマークを行う場合、iexを使わないことが重要です。なぜなら、iexはあなたのコードが実運用環境でどのように使用されているかとは異なる挙動をし、しばしば非常に遅くなるからです。
そこで、benchmark.exsと呼ぶファイルを作成し、その中に以下のコードを追加してみましょう。
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})続いて、ベンチマークを実行するために、次のように呼び出します。
mix run benchmark.exsそして、あなたのコンソールに次のような出力が表示されるはずです。
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
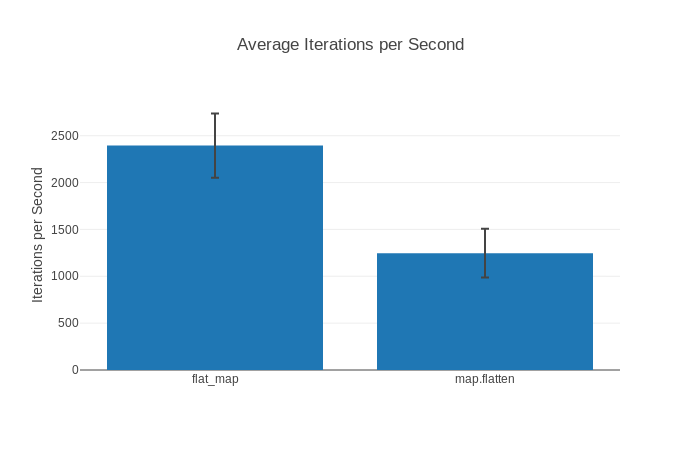
Name ips average deviation median 99th %
flat_map 2.40 K 416.00 μs ±12.88% 405.67 μs 718.61 μs
map.flatten 1.24 K 806.20 μs ±20.65% 752.52 μs 1186.28 μs
Comparison:
flat_map 2.40 K
map.flatten 1.24 K - 1.94x slower +390.20 μsもちろん、ベンチマークを実行しているマシンの仕様によって、システム情報や結果は異なるかもしれませんが、このような一般的な情報はすべて揃っているはずです。
一見したところ、 Comparison セクションでは、私たちの map.flatten バージョンが flat_map より 1.94 倍も遅いことが示されています。また、平均して約390マイクロ秒遅くなっていることもわかり、物事を考えるきっかけになります。知っておくと便利なことばかりです。しかし、他の統計も見てみましょう。
- ips - 「iterations per second」の略で、与えられた関数が1秒間に何回実行されるかを示しています。この指標では、数値が高いほど良いです。
- average - 与えられた関数の平均実行時間です。この指標は、数値が小さいほど良いです。
- deviation - 標準偏差で、各反復の結果がどの程度異なるかを示しています。ここでは、平均値に対する割合で示されています。
-
median - すべての測定時間をソートしたときの中央値(サンプル数が偶数の場合は中央の2つの値の平均)です。環境の不一致のため、これは
averageよりも安定しており、実運用でのコードの通常のパフォーマンスを反映する可能性が多少高くなります。この指標では、数値は低い方が良いです。 - 99th % - 全測定値の99%はこれより速いので、このような最悪な場合のパフォーマンスになっています。低い方が良いです。
他にも利用可能な統計はありますが、この5つがもっとも有用でベンチマークによく使われるため、デフォルトのフォーマッターで表示されるようになっています。 他の利用可能なメトリクスについてもっと知りたい場合は、 hexdocs のドキュメントをチェックしてください。
設定
Bencheeの優れている点の1つは、利用可能なすべての設定オプションです。 ここでは、コード例を必要としないので、まず基本的なことを説明し、その後、Bencheeのもっとも優れた機能の1つであるinputsの使い方を紹介します。
基本
Bencheeは豊富な設定オプションを受け取ります。
もっとも一般的な Benchee.run/2 インターフェイスでは、これらはオプションのキーワードリストの形で第2引数として渡されます。
Benchee.run(%{"example function" => fn -> "hi!" end},
warmup: 4,
time: 10,
inputs: nil,
parallel: 1,
formatters: [Benchee.Formatters.Console],
print: [
benchmarking: true,
configuration: true,
fast_warning: true
],
console: [
comparison: true,
unit_scaling: :best
]
)利用可能なオプションは以下の通りです(hexdocsにも記載があります)。
- warmup - 実際の測定が始まる前に、時間を測定せずにベンチマークシナリオを実行すべき時間を秒単位で指定します。このパラメーターは実行するシステムの”暖気”をシミュレートします。デフォルトは2です。
- time - 各ベンチマークシナリオの実行と計測を行う時間を秒単位で指定します。デフォルトは5です。
- memory_time - すべてのベンチマークシナリオで、メモリ消費を測定する時間を秒単位で指定します。これについては後述します。デフォルトは0です。
-
inputs - 入力名をキーとし、実際の入力を値とする文字列からなるマップです。
{input_name, actual_value}という形式のタプルのリストであることもあります。デフォルトはnil(入力なし)です。これについては、次のセクションで詳しく説明します。 -
parallel - 関数のベンチマークに使用するプロセスの数を指定します。つまり、
parallel: 4と設定すると、4つのプロセスが生成され、与えられたtimeの間、同じ関数を実行します。これらのプロセスが終了すると、次の関数のための新しいプロセスが4つ生成されます。これは同じ時間でより多くのデータを得ることができますが、同時にシステムに負荷をかけ、ベンチマーク結果に干渉します。これは負荷がかかっているシステムをシミュレートするのに便利ですが、予測できない方法で結果に影響を与える可能性があるため、ある程度注意して使用する必要があります。デフォルトは1(並列実行なし)です。 -
formatters - フォーマッターのビヘイビアーを実装したモジュール、当該モジュールとそのオプションのタプル、またはフォーマッター関数のリストを指定します。これらは
Benchee.run/2を使って実行されます。関数は1つの引数(すべてのデータを含むベンチマークスイート)を受け取り、それを使って出力を生成する必要があります。デフォルトは組み込みのコンソールフォーマッターBenchee.Formatters.Consoleです。これについては、後のセクションで詳しく説明します。 - measure_function_call_overhead - 空の関数呼び出しにかかる時間を測定し、測定された各実行時間からこれを差し引きます。非常に高速なベンチマークの精度を高めるのに役立ちます。デフォルトはtrue。
-
pre_check - ベンチマークを測定する前に、各入力(シナリオや各フックの前に与えられたものもすべて含む)で各ジョブを実行し、コードがエラーなく実行されることを確認するかどうかを決定します。これは、スイートの開発中に時間を節約できます。デフォルトは
falseです。 -
save - 現在のベンチマークスイートの結果を、指定した
tagでタグ付けして保存するpathを指定します。Bencheeのドキュメントの保存と読み込みを参照してください。 - load - 現在のベンチマークを比較するために、保存されたスイートをロードします。文字列、文字列のリスト、パターンを指定できます。Bencheeのドキュメントの保存と読み込みを参照してください。
-
print - マップまたはキーワードリストで、以下のオプションをアトムとしてキーと値に
trueまたはfalseを指定します。これにより、アトムで特定される出力が標準的なベンチマーク処理中に表示されるかどうかを制御できます。デフォルトでは、すべてのオプションが有効になっています (true)。オプションは以下の通りです。- benchmarking - Bencheeが新しいジョブのベンチマークを開始するときにプリントされます。
- configuration - ベンチマークを開始する前に、推定総実行時間を含む設定されたベンチマークオプションの概要がプリントされます。
- fast_warning - 関数が非常に高速に実行され、不正確な測定につながる可能性がある場合に警告が表示されます。
-
unit_scaling - 持続時間とカウントの単位を選択するための戦略です。Bencheeは、値をスケーリングする際に、「最適な」単位(結果が少なくとも1になる最大の単位)を見つけます。たとえば、
1_200_000は1.2Mにスケールし、800_000は800Kにスケールします。単位スケーリング戦略は、値のリスト内の個々の値が異なる最適な単位を持つ場合、Bencheeが値のリスト全体に対して最適な単位を選択する方法を決定するものです。4つの方法があり、すべてアトムで指定され、デフォルトは:bestです。- best - もっとも頻繁に使用される最適な単位が使用されます。 同数の場合は、大きい方のユニットが選択されます。
- largest - 最大の最適な単位が使用されます。
- smallest - 最小の最適な単位が使用されます。
- none - 単位のスケーリングを行いません。 Durationsはナノ秒単位で、ipsカウントは単位なしで表示されます。
-
:before_scenario/after_scenario/before_each/after_each- ここではあまり触れませんが、ベンチマーク機能の前後に計測されないように何かをしたい場合は、Bencheeのフックセクションを参照してください。
入力
関数のベンチマークは、その関数が実世界で実際に動作しそうなデータを使って行うことが重要です。
小さなデータセットと大きなデータセットでは、関数の動作が異なることがよくあります。そこで、Bencheeの inputs 設定オプションの出番です。
これにより、同じ関数を好きなだけ異なる入力でテストすることができ、それぞれの関数のベンチマークの結果を見ることができます。
では、もう一度元の例を見てみましょう。
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})この例では、1から10,000までの整数のリストを1つだけ使っています。 これを更新して、いくつかの異なる入力を使用し、より小さいリストとより大きいリストで何が起こるかを見てみましょう。 このファイルを開いて、次のように変更してみましょう。
map_fun = fn i -> [i, i * i] end
inputs = %{
"small list" => Enum.to_list(1..100),
"medium list" => Enum.to_list(1..10_000),
"large list" => Enum.to_list(1..1_000_000)
}
Benchee.run(
%{
"flat_map" => fn list -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn list -> list |> Enum.map(map_fun) |> List.flatten() end
},
inputs: inputs
)
2つの違いにお気づきでしょう。
まず、関数への入力情報を含む inputs マップを持っています。
その入力マップを設定オプションとして Benchee.run/2 に渡しています。
そして、関数が引数を取る必要があるので、ベンチマーク関数も引数を取るように更新する必要があります。
fn -> Enum.flat_map(list, map_fun) endこのようにします。
fn list -> Enum.flat_map(list, map_fun) endもう一度実行してみましょう。
mix run benchmark.exsこれで、コンソールに次のような出力が表示されるはずです。
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: large list, medium list, small list
Estimated total run time: 42 s
Benchmarking flat_map with input large list...
Benchmarking flat_map with input medium list...
Benchmarking flat_map with input small list...
Benchmarking map.flatten with input large list...
Benchmarking map.flatten with input medium list...
Benchmarking map.flatten with input small list...
##### With input large list #####
Name ips average deviation median 99th %
flat_map 13.20 75.78 ms ±25.15% 71.89 ms 113.61 ms
map.flatten 10.48 95.44 ms ±19.26% 96.79 ms 134.43 ms
Comparison:
flat_map 13.20
map.flatten 10.48 - 1.26x slower +19.67 ms
##### With input medium list #####
Name ips average deviation median 99th %
flat_map 2.66 K 376.04 μs ±23.72% 347.29 μs 678.17 μs
map.flatten 1.75 K 573.01 μs ±27.12% 512.48 μs 1076.27 μs
Comparison:
flat_map 2.66 K
map.flatten 1.75 K - 1.52x slower +196.98 μs
##### With input small list #####
Name ips average deviation median 99th %
flat_map 266.52 K 3.75 μs ±254.26% 3.47 μs 7.29 μs
map.flatten 178.18 K 5.61 μs ±196.80% 5.00 μs 10.87 μs
Comparison:
flat_map 266.52 K
map.flatten 178.18 K - 1.50x slower +1.86 μsこれで、入力ごとにグループ化されたベンチマークの情報を見ることができます。 この単純な例では、驚くような洞察は得られませんが、入力サイズによって性能が大きく異なることに驚かれることでしょう。
フォーマッター
これまで見てきたコンソール出力は、関数の実行時間を測定するのに便利な始まりですが、唯一の選択肢ではありません このセクションでは、他の3つのフォーマッターについて簡単に説明し、あなたが好きなようにフォーマッターを書くために必要なことについても触れます。
他のフォーマッター
Bencheeはコンソールフォーマッターを内蔵しており、これはすでに見たとおりですが、その他に公式にサポートされているフォーマッターは以下の3つです。
それぞれ、期待通りの働きをします。つまり、結果を指定されたファイル形式に書き出すので、好きな形式で結果をさらに処理できます。
これらのフォーマッターはそれぞれ別のパッケージなので、それらを使用するには mix.exs ファイルに依存関係として以下のように追加する必要があります。
defp deps do
[
{:benchee_csv, "~> 1.0", only: :dev},
{:benchee_json, "~> 1.0", only: :dev},
{:benchee_html, "~> 1.0", only: :dev}
]
end
benchee_json と benchee_csv はシンプルですが、benchee_html は実はとても充実した機能を備えています!
また、PNG画像としてエクスポートすることもできます。
もし興味があれば、htmlレポートの例をチェックしてみてください。このようなグラフが含まれています。
3つのフォーマッターは、それぞれのGitHubのページで十分に説明されているので、ここではその詳細については説明しません。
独自のフォーマッター
もし、提供されている4つのフォーマッターで物足りない場合は、カスタムフォーマッターを作成することも可能です。
フォーマッターを書くのはとても簡単です。
必要なのは、 %Benchee.Suite{} 構造体を受け取る関数を書くことで、そこから好きな情報を引き出すことができます。
この構造体の中身については、GitHub や HexDocs で見ることができます。
このコードベースは十分に文書化されており、カスタムフォーマッターを書くためにどのような種類の情報が利用できるかを確認したい場合には、簡単に読むことができます。
また、Benchee.Formatter behaviour を採用した、よりフルに機能を持ったフォーマッターを書くこともできますが、ここではより単純な関数バージョンにこだわることにします。
とりあえず、カスタムフォーマッターの簡単な例として、以下のようなものを紹介します。 たとえば、各シナリオの平均実行時間を表示する、非常にシンプルなフォーマッターが欲しいとしましょう。これは次のようになります。
defmodule Custom.Formatter do
def output(suite) do
suite
|> format
|> IO.write()
suite
end
defp format(suite) do
Enum.map_join(suite.scenarios, "\n", fn scenario ->
"Average for #{scenario.job_name}: #{scenario.run_time_data.statistics.average}"
end)
end
endそして、このようにベンチマークを実行できます。
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
formatters: [&Custom.Formatter.output/1]
)そして、独自のフォーマッターで実行すると、次のようになります。
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Average for flat_map: 419433.3593474056
Average for map.flatten: 788524.9366408596メモリ
ここまで来て、Bencheeのもっともクールな機能の1つであるメモリ測定をお見せせずに終わってしまいました。
Bencheeはメモリ消費を測定できますが、それはベンチマークが実行されているプロセスに限定されます。他のプロセス(ワーカープールなど)でのメモリ消費を追跡することは今のところできません。
メモリ消費量には、ベンチマークシナリオが使用したすべてのメモリが含まれ、ガベージコレクションされたメモリも含まれるため、必ずしもプロセスの最大メモリサイズを表しているわけではありません。
どのように使用するのですか?それは、:memory_time オプションを使うだけです。
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 0 ns
time: 0 ns
memory time: 1 s
parallel: 1
inputs: none specified
Estimated total run time: 2 s
Benchmarking flat_map...
Benchmarking map.flatten...
Memory usage statistics:
Name Memory usage
flat_map 624.97 KB
map.flatten 781.25 KB - 1.25x memory usage +156.28 KB
**All measurements for memory usage were the same**見ての通り、Bencheeは採取したサンプルがすべて同じであるため、わざわざすべての統計情報を表示する必要はないのです。これは、関数にランダム性が含まれていない場合、実はよくあることなのです。もし、統計値がいつも同じであれば、何の役に立つでしょうか?
間違いを報告したい、あるいはこのレッスンに貢献したい? このレッスンをGitHubで編集しよう!